Java/GradleでANTLRを使い、DDLからテーブル定義書を作成、その3
リスナー方式に変更
どうもコメントを拾うには、これまでのやり方ではだめのようだ。リスナーを使う必要があるらしい。そこで、以下のように変更してみる。
import org.antlr.v4.runtime.*;
import org.antlr.v4.runtime.tree.*;
import mysqlparser.*;
public class TestMain {
static String SQL =
"select count(*) from tblbook; insert into tblbook (a, b) values(1, 2)";
public static void main(String[] args) {
// 字句解析を行う
MySqlLexer lexer = new MySqlLexer(CharStreams.fromString(SQL.toUpperCase()));
// 字句解析の結果を構文解析する
CommonTokenStream stream = new CommonTokenStream(lexer);
MySqlParser parser = new MySqlParser(stream);
// リスナーを作成
MySqlParserBaseListener listener = new MySqlParserBaseListener() {
@Override public void enterSqlStatement(MySqlParser.SqlStatementContext ctx) {
System.out.println("" + ctx.getText());
}
};
// ウォーカーで構文木をたどっていき、リスナーで構文要素を得る
ParseTreeWalker walker = new ParseTreeWalker();
walker.walk(listener, parser.root());
}
}
出力結果は以下になる。
SELECTCOUNT(*)FROMTBLBOOK
INSERTINTOTBLBOOK(A,B)VALUES(1,2)
コメントを拾う
で、以下の本の「12.1 Broadcasting Tokens on Different Channels」を見てみる。
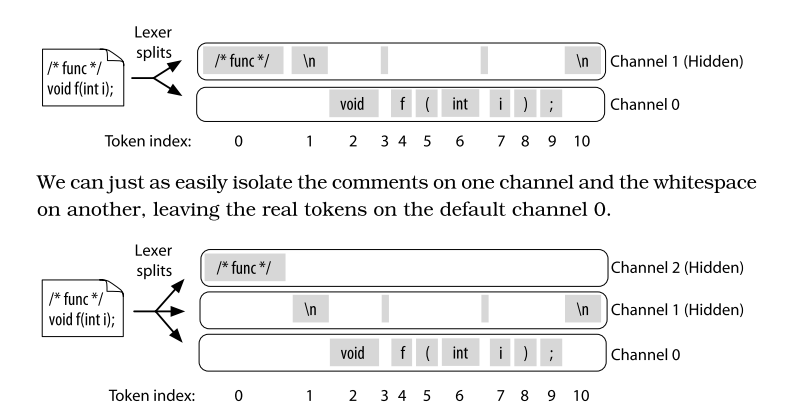
つまり、単にコメントやら空白やらをスキップすると、本体のChannel 0とは別のChannel 1に入っていくのだが、特にコメントを保持したい場合には、さらに空白とは別のチャンネルに入れる。
それが上の図の後者の状況だ。しかし、この場合でもトークンインデックスは同じになっている。つまり、本体の「void」のインデックスは2であり、コメントを得たい場合には、コメントチャンネルでvoidの左側のインデックスを見れば良いということになる。
そこで、次のように変更してみる。
import java.util.*;
import org.antlr.v4.runtime.*;
import org.antlr.v4.runtime.tree.*;
import mysqlparser.*;
public class TestMain {
static String SQL =
"/*! this is test */ \n" +
"select count(*) from tblbook; insert into tblbook (a, b) values(1, 2)";
public static void main(String[] args) {
// 字句解析を行う
MySqlLexer lexer = new MySqlLexer(CharStreams.fromString(SQL.toUpperCase()));
// 字句解析の結果を構文解析する
CommonTokenStream stream = new CommonTokenStream(lexer);
MySqlParser parser = new MySqlParser(stream);
// リスナーを作成
MySqlParserBaseListener listener = new MyListener(stream);
// ウォーカーで構文木をたどっていき、リスナーで構文要素を得る
ParseTreeWalker walker = new ParseTreeWalker();
walker.walk(listener, parser.root());
}
static class MyListener extends MySqlParserBaseListener {
final BufferedTokenStream tokens;
MyListener(BufferedTokenStream tokens) {
this.tokens = tokens;
}
@Override public void enterSqlStatement(MySqlParser.SqlStatementContext ctx) {
Token sqlToken = ctx.getStart();
int sqlTokenIndex = sqlToken.getTokenIndex();
List<Token>hiddenTokens =
tokens.getHiddenTokensToLeft(sqlTokenIndex, MySqlLexer.MYSQLCOMMENT);
if (hiddenTokens != null && hiddenTokens.size() > 0) {
System.out.println("mysqlcomment[" + hiddenTokens.get(0).getText() + "]");
}
System.out.println("" + ctx.getText());
}
}
}
入力にはMYSQLコメント「/*! this is test */」がSQLステート麺との前に付けられている。そして、SQLステートメントがやってきたら、コメントチャンネルを見に行き「左」のものを見る。
結果は以下になった。これでOKだ。
mysqlcomment[/*! THIS IS TEST */]
SELECTCOUNT(*)FROMTBLBOOK
INSERTINTOTBLBOOK(A,B)VALUES(1,2)
コメント字句解析の定義を変更する。
以下になっているのを、
channels { MYSQLCOMMENT, ERRORCHANNEL }
// SKIP
SPACE: [ \t\r\n]+ -> channel(HIDDEN);
SPEC_MYSQL_COMMENT: '/*!' .+? '*/' -> channel(MYSQLCOMMENT);
COMMENT_INPUT: '/*' .*? '*/' -> channel(HIDDEN);
LINE_COMMENT: (
('-- ' | '#') ~[\r\n]* ('\r'? '\n' | EOF)
| '--' ('\r'? '\n' | EOF)
) -> channel(HIDDEN);
以下に変更する
channels { MYCOMMENT, ERRORCHANNEL }
// SKIP
SPACE: [ \t\r\n]+ -> channel(HIDDEN);
SPEC_MYSQL_COMMENT: '/*!' .+? '*/' -> channel(MYCOMMENT);
COMMENT_INPUT: '/*' .*? '*/' -> channel(MYCOMMENT);
LINE_COMMENT: (
('-- ' | '#') ~[\r\n]* ('\r'? '\n' | EOF)
| '--' ('\r'? '\n' | EOF)
) -> channel(MYCOMMENT);
次のように変更する。
import java.util.*;
import org.antlr.v4.runtime.*;
import org.antlr.v4.runtime.tree.*;
import mysqlparser.*;
public class TestMain {
static String SQL =
"/* this is test */ \n" +
"select count(*) from tblbook;\n" +
"-- this is comment\n" +
"insert into tblbook (a, b) values(1, 2);" +
"/*! MySql comment */ SELECT * FROM SAMPLE";
public static void main(String[] args) {
// 字句解析を行う
MySqlLexer lexer = new MySqlLexer(CharStreams.fromString(SQL.toUpperCase()));
// 字句解析の結果を構文解析する
CommonTokenStream stream = new CommonTokenStream(lexer);
MySqlParser parser = new MySqlParser(stream);
// リスナーを作成
MySqlParserBaseListener listener = new MyListener(stream);
// ウォーカーで構文木をたどっていき、リスナーで構文要素を得る
ParseTreeWalker walker = new ParseTreeWalker();
walker.walk(listener, parser.root());
}
static class MyListener extends MySqlParserBaseListener {
final BufferedTokenStream tokens;
MyListener(BufferedTokenStream tokens) {
this.tokens = tokens;
}
@Override public void enterSqlStatement(MySqlParser.SqlStatementContext ctx) {
Token sqlToken = ctx.getStart();
int sqlTokenIndex = sqlToken.getTokenIndex();
List<Token>hiddenTokens =
tokens.getHiddenTokensToLeft(sqlTokenIndex, MySqlLexer.MYCOMMENT);
if (hiddenTokens != null && hiddenTokens.size() > 0) {
System.out.println("comment[" + hiddenTokens.get(0).getText() + "]");
}
System.out.println("" + ctx.getText());
}
}
}
結果は以下になる。
comment[/* THIS IS TEST */]
SELECTCOUNT(*)FROMTBLBOOK
comment[-- THIS IS COMMENT
]
INSERTINTOTBLBOOK(A,B)VALUES(1,2)
comment[/*! MYSQL COMMENT */]
SELECT*FROMSAMPLE