Motokoプログラミング1
Motokoプログラミング(準備2)の続きである。
レプリカ、キャニスターとは何か?
ここで概念的な事柄を説明しようと思うのだが、私自身も良くわかっていないので間違いがあるかもしれない。しかし、わからなくともプログラミングには、基本的には支障はない。出てくるとすれば、直行永続性の扱い方になるだろうが、これが実際にどうやって処理されているのか、今の時点では不明。
レプリカとは
ノードとは、インターネット・コンピュータの一部として動作する物理的なマシンのこと。レプリカは、ノード上で動作するインターネットコンピュータソフトウェアのインスタンスで、インターネット・コンピュータ・プロトコル(ICP)を実装しています。つまり、ノードはハードウェアで、レプリカはソフトウェア。
もうひとつ、ちょっとした違いがある。すべてのノードは1つのサブネットに属する(必ずしも同じとは限らない)。サブネットに属するすべてのノードが、状態や計算を複製してコンセンサスを得る。そのため、「レプリカ」という言葉になっている。そのため、レプリカはサブネットの文脈で使われることが多いが、ノードはより一般的に、つまりノード・プロバイダーやトークノミクスなどの文脈で使われる。
つまり、レプリカは仮想マシンのようなものと考えれば良いと思われる。これが、実際のマシン(ノード)で動作するのだが、複数のノードがサブネットを構成しており、レプリカはそれらのあいだで複製されるらしい。
しかし、当然のことながら、開発環境において、レプリカは一つしか作成されない。
キャニスターとは
キャニスターとは、レプリカという仮想マシンの中で実行されるプロセスと考えて良いと思われるが、この形式としては、WebAssemblyという仮想マシンの機械語のようなものであるらしい。
そして、通常のウェブアプリを作成する場合には、フロントエンドとバックエンドがそれぞれ別のキャニスターとなるらしい。これらの間でCandidによる通信が行われると考えられる。
開発環境では
開発環境では、先の通り、単一のレプリカを起動させ、その中にコンパイル済のWebAssemblyコードを配置することになる。
前者は「dfx start」で行い、レプリカが起動している間に「dfx deploy」を行うことによってキャニスターが配置される。
この説明は正しく無いかもしれないが、現在のところはこんな理解で構わないだろう。
helloプログラムの解析
サンプルで作成されるプログラムは以下のようなものだ。
actor {
public query func greet(name : Text) : async Text {
return "Hello, " # name # "!";
};
};
- actorは一つのキャニスター(この場合はバックエンドキャニスター)を表している。
- funcは関数定義、publicはこの関数を外側に公開することを示す。
- queryは値を返すfuncには必ず必要と思われる。また、asyncも必ず必要と思われる。この意味としては、「値を返すが、非同期である」ということだ。
- サンプルでは、入力された文字列の前に”Hello, “をつけて返しているが、#が文字列接続のオペレータらしい。
ちなみに、このプログラムを変更して、それを再度デプロイするには「dfx deploy」すれば良いのだが、エラーが発生すると配備はできない。queryやasyncを削除してみるとエラーが発生するので、これらは省略できないようだ。
変更してみる
少々変更して、以下のようにしてみる。
import D "mo:base/Debug";
actor {
// アクターの開始。これは一行コメント
D.print("actor starting");
/* カウンター
これは複数行コメント
*/
var counter:Nat = 0: Nat;
/* 番号付きでエコーバックする */
public query func greet(name : Text) : async Text {
D.print("greet " # name);
return "Hello, " # name # "! " # debug_show(counter);
};
/* カウンターをリセットする */
public func reset() {
counter := 0;
D.print("counter reset");
};
/* カウンターをインクリメント */
public func inc() {
counter += 1;
D.print("counter incremented to " # debug_show(counter));
};
/* アクターが開始された */
D.print("actor started");
};
何をしているかは一目瞭然だろう。
- コメントはJava風と同様に書ける
- ベースモジュールをインポートし、それに適当な名前を付けてアクセスできる。
- counterは自然数(Nat)型としたが、このケースでは、省略して「var counter = 0;」と書いてもよい。
- 代入は「=」ではなく「:=」。「=」は、あくまでも初期化に使うらしい。
これを起動すると、dfx startを行った方の端末に以下が表示される。
[Canister qsgjb-riaaa-aaaaa-aaaga-cai] actor starting
[Canister qsgjb-riaaa-aaaaa-aaaga-cai] actor started
バックエンドのUIを見てみると、以下のような表示になる。つまり、publicとした関数が自動的にAPIとして公開されるようになる。
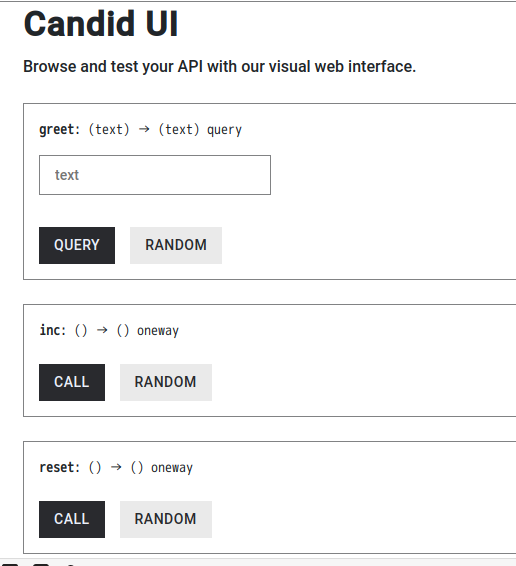
ちなみに、これらのコメントや基本的なデータタイプについては、Motoko Language Tourに説明がある。
stableタイプ
通常のプログラムと同様に、通常の変数はプログラムが再起動すると初期化される。例えば、上のプログラムを「dfx deploy」すれば、その都度counterの値は0に戻されてしまう。
これに対して、変数をstableに指定すると、いくら「dfx deploy」してもその時点の値は変更されない。つまり、永続化されている。これは、orthogonal persistenceと呼ばれるものだそうだ。例えば以下のように定義する。
stable var counter:Nat = 0: Nat;
こうすると、「dfx deploy」を繰り返し行っても、その時点の値が保持されるどころか、レプリカを再起動しても保持される。開発環境とはいえ、これも実際のレプリカの挙動をシミュレートしたものだろう。
Stable variables and upgrade methodsに説明がある。
以下は、上ページのTypying以下のほぼ機械翻訳
コンパイラは、(dfx deployによる)アップグレード後の置き換えプログラムにおいて、stable変数が互換性を持ち、かつ意味を持つことを保証しなければならないため、安定状態には以下の型制約が適用されます。
- すべてのstable変数にはstableな型が必要です。
ここで型は,その中の任意の var 修飾子を無視して得られる型がsharedの場合にstableとなります(意味不明).
このように,stable型とshared型の唯一の違いは,前者が変化をサポートすることです.shared型と同様,stable型は一次データに限定され,ローカル関数とローカル関数から構築される構造体(オブジェクトなど)は除外されます.このように関数を除外する必要があるのは,データとコードの両方で構成される関数の値の意味はアップグレードの際に容易に保存できないのに対し,平文のデータの意味は変化可能かどうかにかかわらず保存できるからです.
注意:一般に、オブジェクト型はローカル関数を含むことができるため、stableではありません。しかし、安定したデータのプレーンなレコードは、オブジェクト型の特別なケースとしてstableなものとなっています。さらに、アクターやshared関数への参照も安定しているため、アップグレードをまたいでその値を保持することができます。たとえば、サービスを購読しているアクターや共有関数のコールバックのセットを記録する状態を保持することができます。
上記は日本語にしても少々意味がとりづらい。おいおい見ていくことにする。