SolrのDataImportHandler例を動作させる
SolrにはDataImportHandlerという機能があり、これは「いちいちクライアント側(この場合はSolrを利用する側のプログラム)で、個別のインデックス登録を指示しなくとも、Solrが勝手にRDBに接続して勝手に登録してくれる」という夢のような機能である。
もちろん、そうはうまく行かないであろうことは想像がつくが、しかし、利用プログラム側で登録動作をしなくて良い点は楽かと思う。こちらは単純に、従来のRDB登録とSolrでの検索のみを行えば良いのだ。
もちろん、これまでにわかっていることは、
- Solr側の設定としてRDB接続アカウントを指定してやる必要がある。
- RDBからデータを拾い出すSQLを指定してやる必要がある。
- 特に更新(DeltaImportと呼ばれるらしい)をサポートするためには、テーブルのフィールドとして更新日時timestampが必要らしい。
ともあれ、Solrにあらかじめ組み込まれているDataImportHandlerの例を動作させてみる。
結論
最初に結論だが、この機能は使いものにならない。こちらとしては、これをやりたいわけだ。
- 最初にすべてのデータについてインデックスを作ってほしい
- それ以降については、追加や更新されたものについてインデックスを作って欲しい
のだが、これを行わせるためには、
- おそらくその起動を指示しなければならない
- 追加・更新時の処理としては、タイムスタンプを見て行う。つまり、その都度すべてのレコードがスキャンされる
ということだ。したがって「定期的に」行わせることになるのだが、その間隔をどの程度にするかが問題になる。
- やりすぎても無駄になるし、やらなすぎると検索に反映されなくなる
ということになる。したがって、この機能に頼らず、「何らかの追加・更新・削除があった場合には、それを独自に記録しておき、その記録レコードが存在すれば、ただちにインデックスのメンテナンスをする」という方針の方が明らかに有利である。
したがって、この機能を使う必要はない。
solr.solr.home
Solrのフォルダ構造で見たように、通常の動作としてはSolrはインストールディレクトリ下のserver/solrフォルダをコア格納フォルダとする(正式には何と呼ばれるのかわからないが)。これはsolr.solr.homeと呼ばれるらしい。
いわば、server/solrの中に複数のインデックスデータベースがあるイメージである。その上のserver直下のフォルダには、logsのようにログを格納するフォルダがある。
solr.solr.homeフォルダはどの場所でも良いようだ。これは、solrコマンドの-s引数で変更できる。
example-DIH
さて、example/example-DIH/solrにDataImportHandlerの例があるのだが、このフォルダ自体がコア格納フォルダ。このため、solr.solr.homeフォルダとしてこの場所を指定すればsolrはこれをコアフォルダとして認識して動作する。
つまり、今solrのインストールが「c:\solr」だとすると、このフォルダは「C:\solr\example\example-DIH\solr」になっている。したがって、ここをsolr.solr.homeに指定してSolrを起動するには、
solr start -s C:\solr\example\example-DIH\solr
とすればよい。Solrはデフォルトの場所を綺麗サッパリ忘れ、このサンプルの場所を相手にするようになる。
ただし、同じことをもっと簡単なコマンドで行うことができる。このバッチファイル(シェルスクリプト)には、あらかじめサンプルの場所の知識があるようで、以下でもよい。
solr -e dih
ともあれ、この状態でlocalhost:8983を見てみると、このサンプル内に用意されたコア(のみ)が表示される。
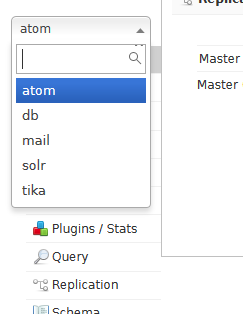
これはもちろん、example-DIH/solr下のフォルダに一致している。
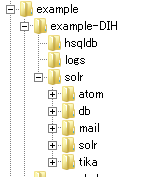
DataImportHandlerの設定ファイル
上記のコアのそれぞれがDataImportHandlerの例なのだが、その設定としては、以下のようである。
それぞれのコアフォルダのconfフォルダにはsolrconfig.xmlという設定ファイルがある。これは、そのコアの個別の設定を記述するファイルらしい。ここに、data import handler関連の設定ファイルの名称を記述してやる。
例えば、atom/conf/solrconfig.xmlの場合だと。
<requestHandler name="/dataimport" class="solr.DataImportHandler">
<lst name="defaults">
<str name="config">atom-data-config.xml</str>
<str name="processor">trim_text</str>
</lst>
</requestHandler>
との記述があり、同じフォルダのatom-data-config.xmlには、何やらStackOverflowのatomフィードを取得する定義があるようだ。
atomフィードの取得例
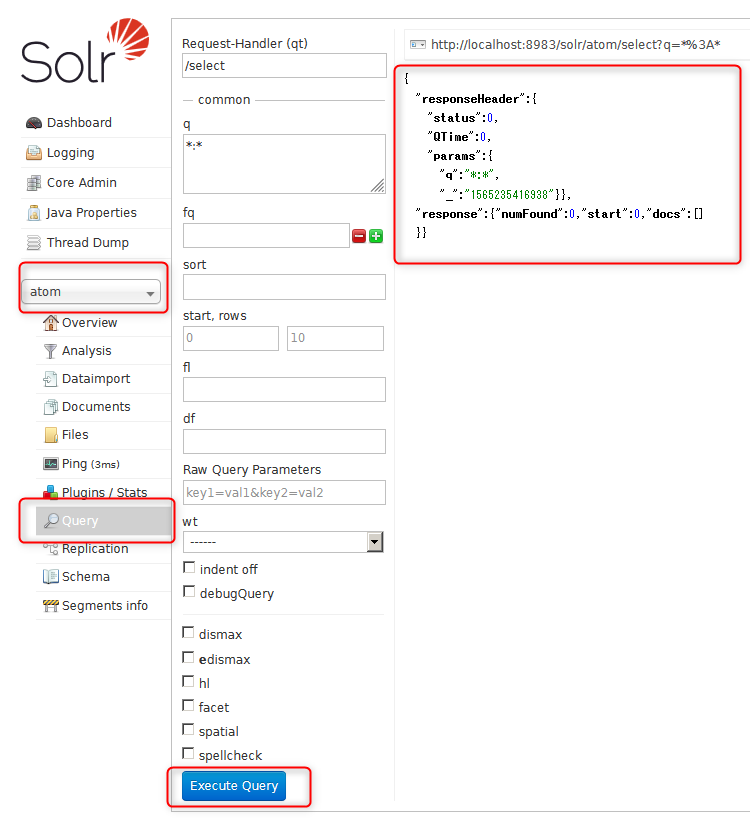
このatomフィードのData Import Handlerを動作させてみる。まずはQueryでほぼ何も無いことを確認する。何の条件も指定せずに単にExecute Queryをクリックするだけだ。
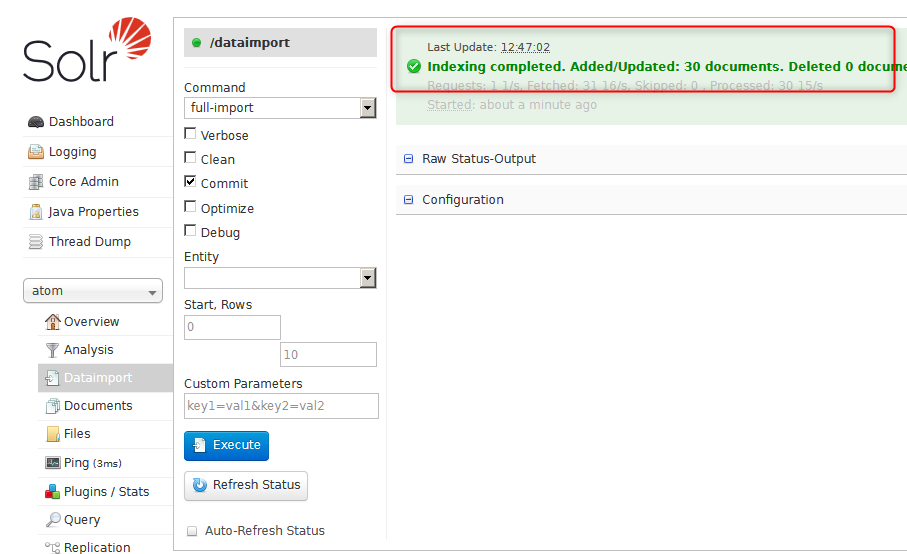
次にDataImportのExecuteをクリックする。右上にindexingという表示が現れる。
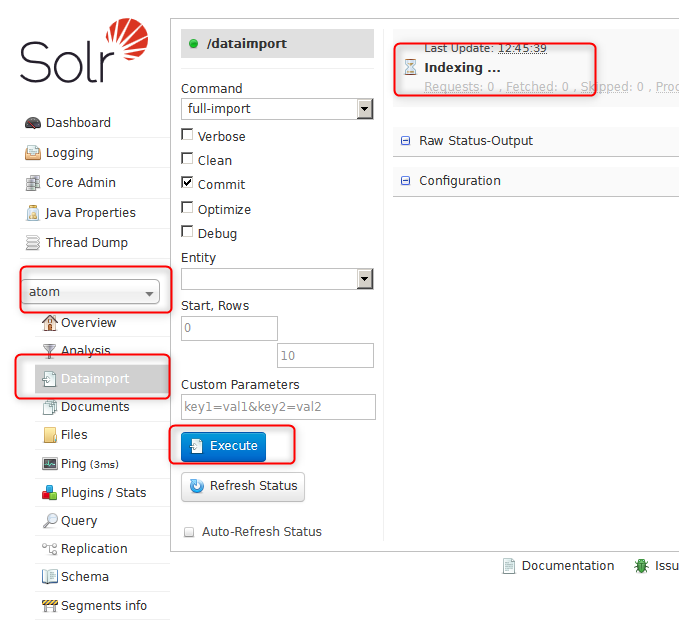
このとき、atomフォルダ下のindexフォルダを見てみると、Luceneのインデックスが形成されていることがわかる。
インデックスづけが終了すると、こんなメッセージになる。対象は30個のみだったようだ。どういう条件で取得したのかわからないのだが。
最初と同じく条件を指定せずにQueryを実行すると、今度はいくばくかのドキュメントが出てくる。
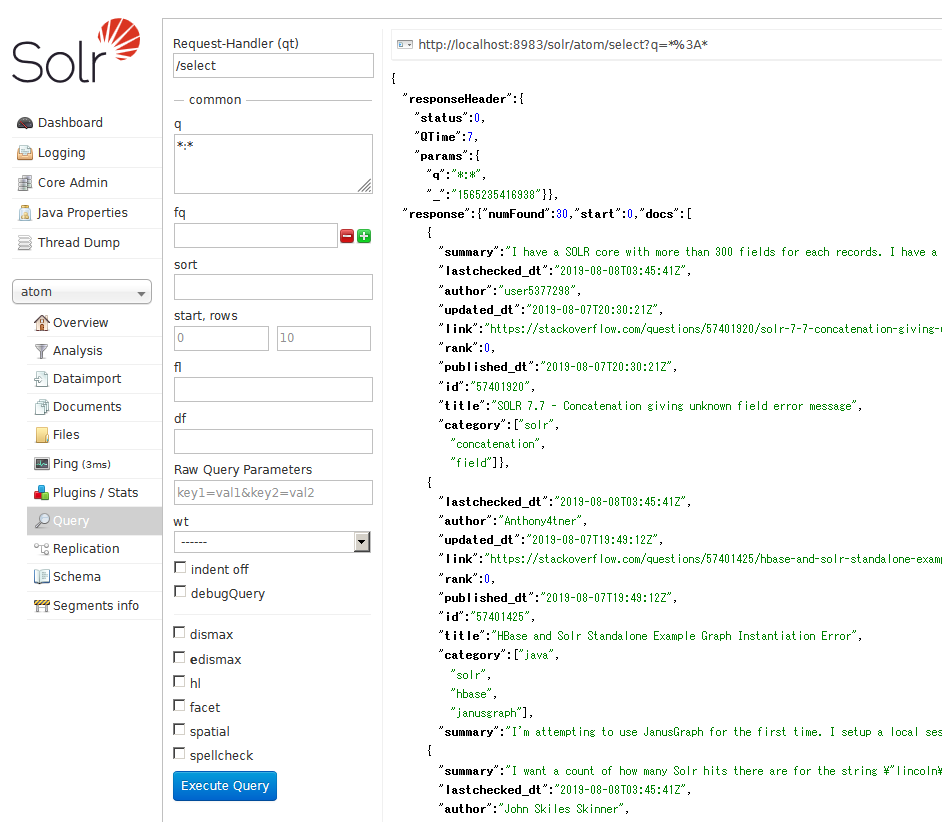
この例でわかることとしては、データを引っ張ってくるのは特にRDBに限らないということだ。ここでは、ウェブサイトのatomフィードを取得している。
dbの例
こちらは、Dbからデータ取得する例のようだが、操作としてはatomの場合と同じだ。単純にDataImportを行うとインデックスが作成され、検索が行えるというものだ。
問題は設定ファイルの構造である。以下に詳細が記述されている。
これについては次回見ていく。